10 Recursos do Istio que Você Provavelmente Não Usa
O que é Istio
Istio é um service mesh para Kubernetes. Ele intercepta todo tráfego entre seus serviços e adiciona capacidades que sua aplicação não precisa implementar: mTLS automático, métricas, tracing, controle de tráfego.
Funciona assim. Um proxy sidecar (Envoy) é injetado em cada pod do seu cluster. Esse proxy captura todo tráfego de entrada e saída. O control plane do Istio configura esses proxies. (Existe também um “ambient mode” mais novo que remove o sidecar. Assunto pra outro post.)
O resultado: observabilidade, segurança e controle de tráfego sem mudar uma linha de código na aplicação.
Três recursos básicos:
- Gateway: expõe serviços para fora do cluster
- VirtualService: define regras de roteamento
- DestinationRule: configura políticas de tráfego para um destino
Se você só usa esses, está perdendo 80% do que o Istio pode fazer.
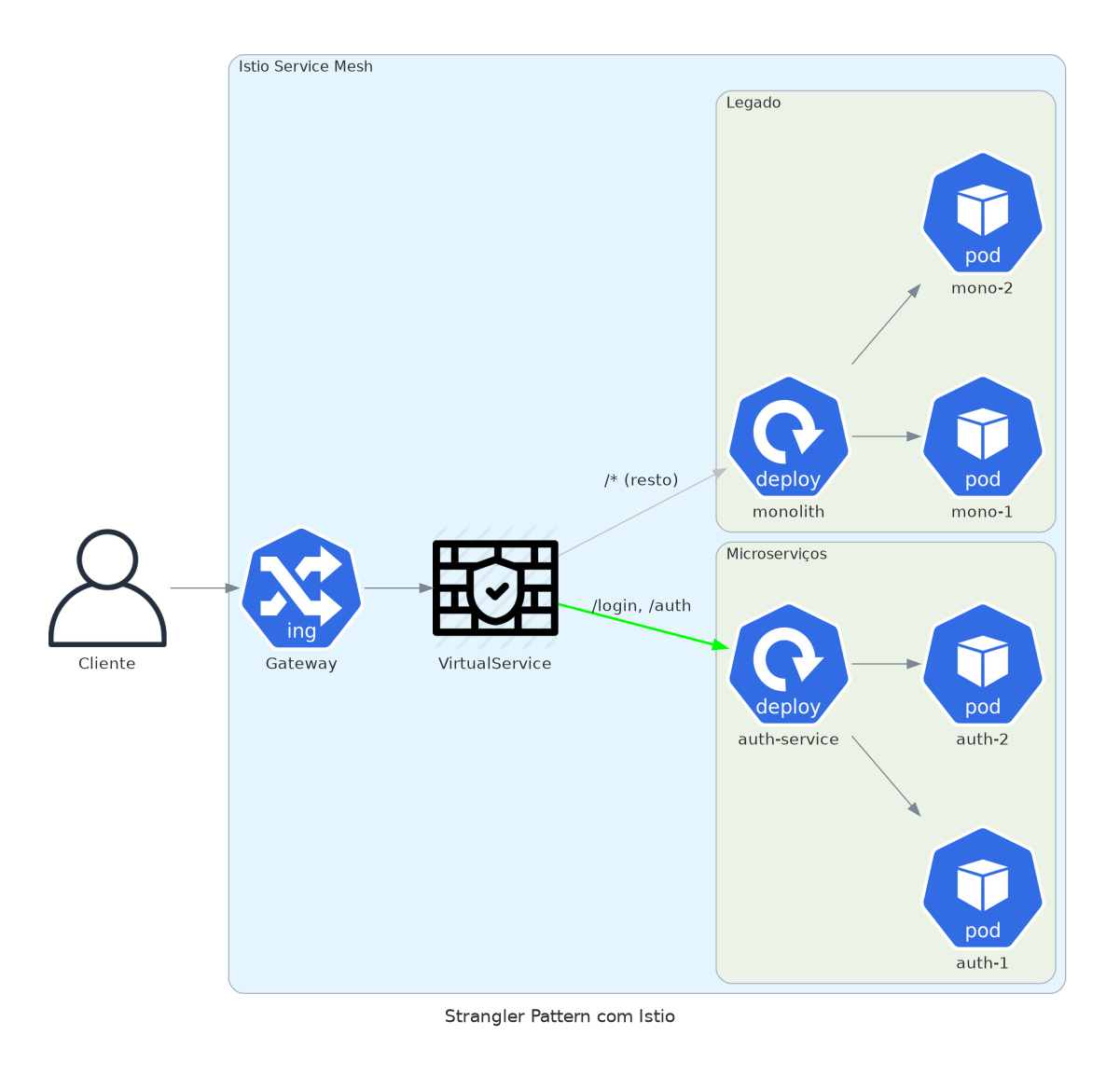
1. Strangler Pattern
Você tem um monolito em api.seudominio.com. Quer extrair /login para um microserviço. Sem mexer em DNS. Sem downtime.
O strangler pattern permite migrar funcionalidades do monolito para microserviços de forma incremental. Em vez de uma reescrita arriscada, você roteia paths específicos para novos serviços enquanto mantém o resto no sistema legado.
O VirtualService atua como roteador. Primeiro match vence. Coloque suas rotas específicas primeiro, depois um catch-all para o monolito.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: api-strangler
spec:
hosts:
- api.seudominio.com
http:
- match:
- uri:
prefix: "/login"
- uri:
prefix: "/auth"
route:
- destination:
host: auth-service.auth.svc.cluster.local
port:
number: 8080
- route:
- destination:
host: monolith.legacy.svc.cluster.local
port:
number: 80Rotas específicas vão pro microserviço. O resto continua no monolito. Rollback é deletar o VirtualService. Zero coordenação necessária com o time do legado.
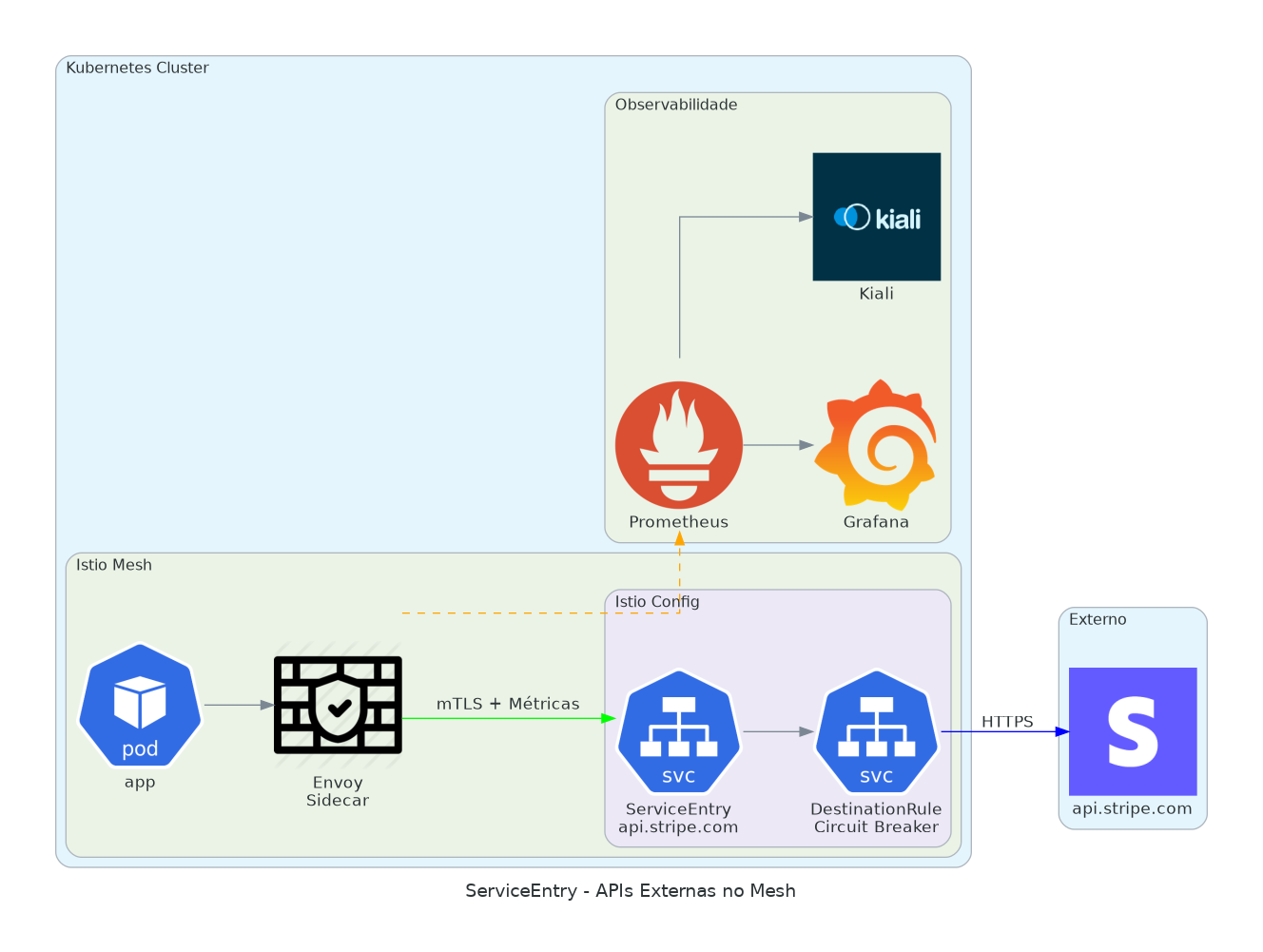
2. ServiceEntry para APIs Externas
Chamadas para Stripe, AWS, qualquer API externa. Você quer métricas. Circuit breaker. Observabilidade no Kiali.
Por padrão, o Istio não conhece serviços externos. Eles não aparecem no seu service graph. Você não pode aplicar políticas de tráfego neles. ServiceEntry muda isso.
Uma vez que você declara um serviço externo, o Istio trata ele como qualquer outro serviço no seu mesh. Você ganha histogramas de latência, taxas de erro, limites de connection pool. Quando o Stripe tiver uma queda, você vai ver no Grafana antes dos usuários reclamarem.
apiVersion: networking.istio.io/v1
kind: ServiceEntry
metadata:
name: stripe-api
spec:
hosts:
- api.stripe.com
location: MESH_EXTERNAL
ports:
- number: 443
name: https
protocol: TLS
resolution: DNS
---
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: stripe-api-dr
spec:
host: api.stripe.com
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
h2UpgradePolicy: UPGRADE
http1MaxPendingRequests: 50
outlierDetection:
consecutive5xxErrors: 5
interval: 30s
baseEjectionTime: 60sA DestinationRule adiciona um circuit breaker. Se o Stripe retornar 5 erros 5xx consecutivos, o Istio para de enviar requests por 60 segundos. Sua aplicação recebe falhas rápidas em vez de conexões travadas.
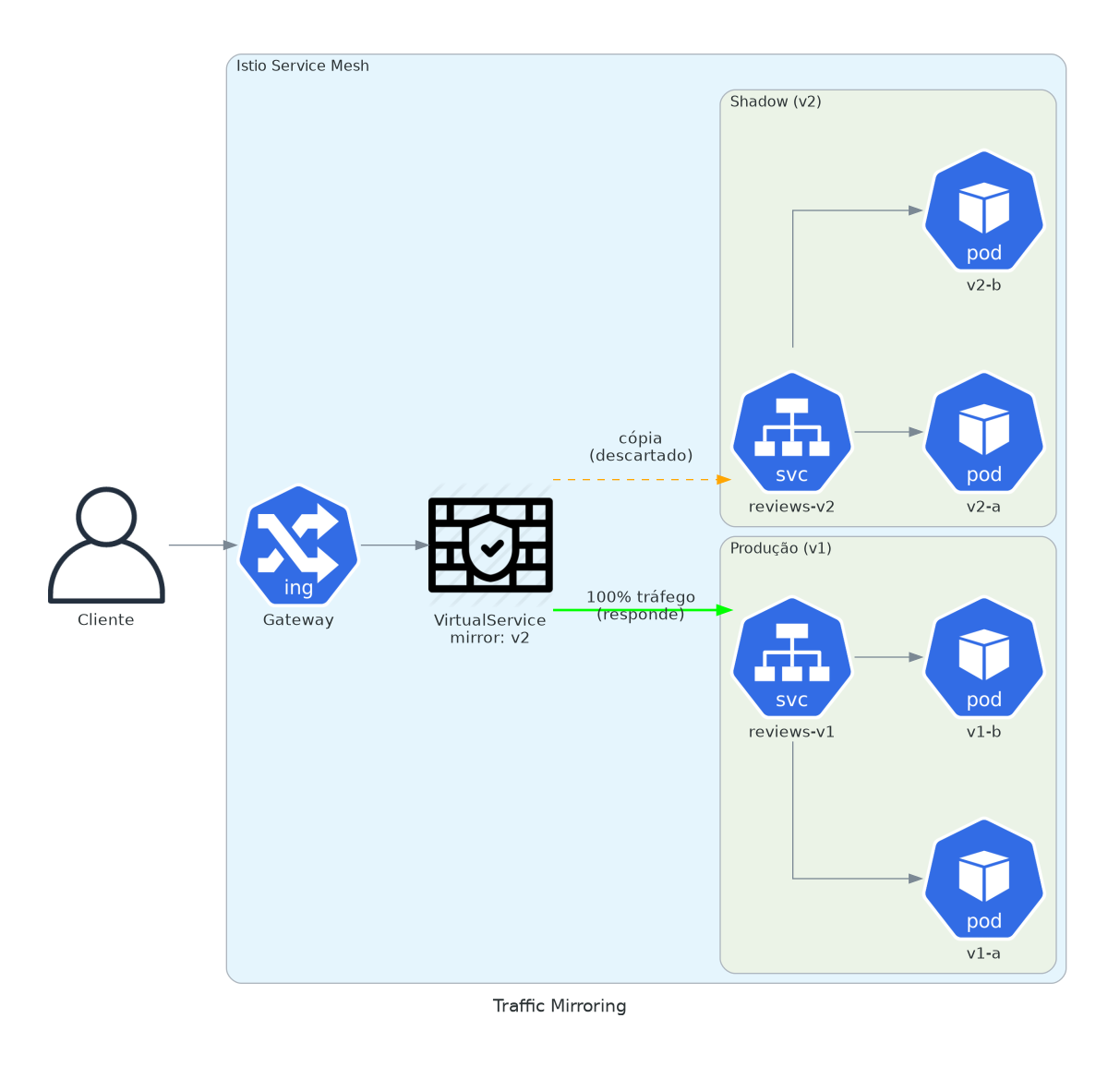
3. Traffic Mirroring
Nova versão do serviço. Você quer testar com tráfego real. Sem afetar usuários.
Shadow testing é subestimado. Você deploya v2 ao lado de v1. Tráfego real de produção atinge ambos. Mas só respostas de v1 voltam pros usuários. Respostas de v2 são descartadas.
O que você ganha: teste de carga real, dados reais, edge cases reais. Seu ambiente de staging mente pra você. Tráfego de produção não.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: reviews-mirror
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
weight: 100
mirror:
host: reviews
subset: v2
mirrorPercentage:
value: 100.0Observe logs e métricas de v2. Se ele processa o tráfego corretamente, prossiga pro canary. Se ele crasha sob carga, você pegou isso antes de qualquer usuário perceber. Os requests espelhados são fire-and-forget. Eles adicionam latência a v2, não ao cliente.
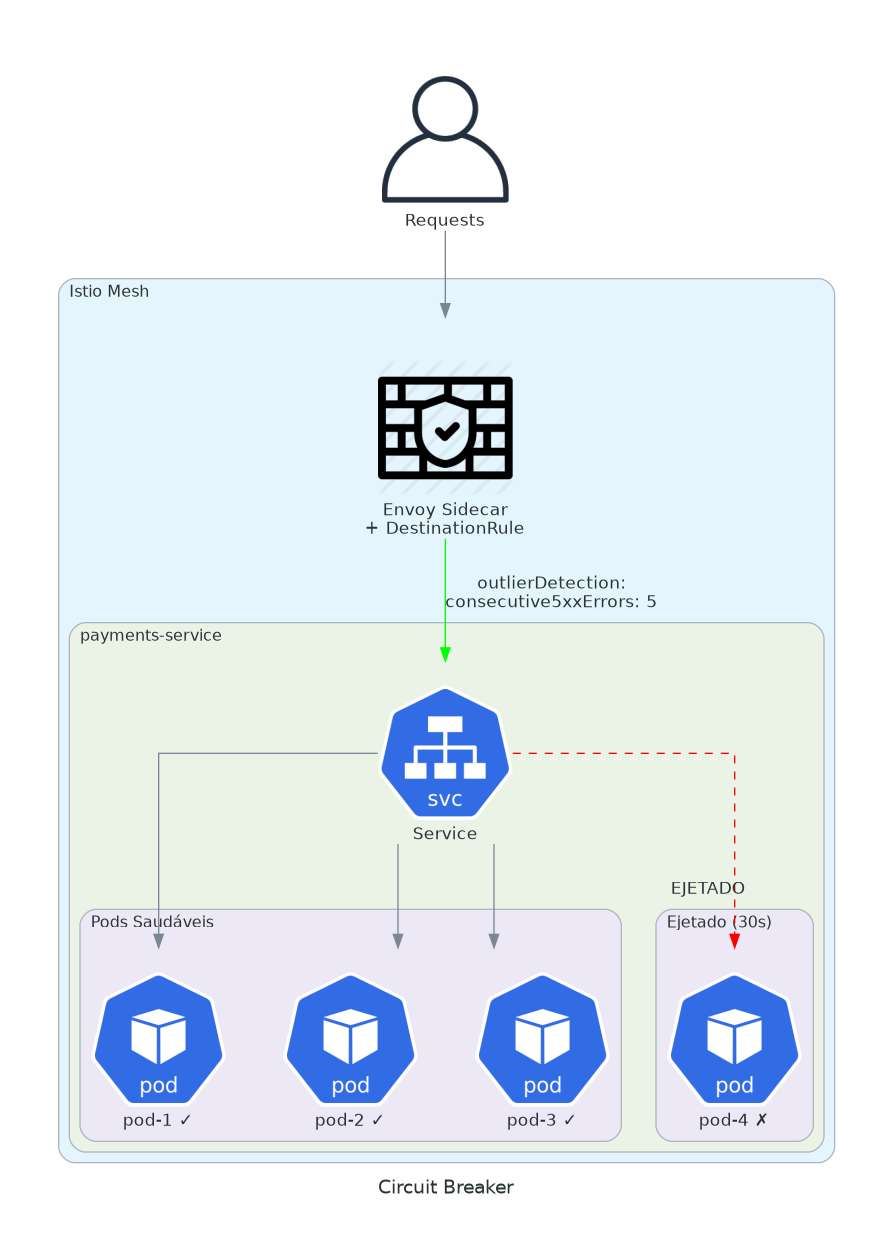
4. Circuit Breaker
Um pod lento derruba a cadeia inteira. Requests enfileiram. Timeouts propagam. Cascata.
Sistemas distribuídos falham de formas distribuídas. Uma query lenta no banco deixa um pod lento. Quem chama espera. Quem chama quem chama espera. Eventualmente sua plataforma inteira está esperando um pod.
Circuit breakers param a cascata. Se um pod está unhealthy, remova ele do pool. Falha rápida é melhor que falha lenta.
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: payments-circuit-breaker
spec:
host: payments-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
http1MaxPendingRequests: 50
http2MaxRequests: 100
maxRequestsPerConnection: 10
maxRetries: 3
outlierDetection:
consecutive5xxErrors: 5
interval: 10s
baseEjectionTime: 30s
maxEjectionPercent: 50
minHealthPercent: 30Cinco erros 5xx consecutivos: pod ejetado por 30 segundos. Tráfego redirecionado para pods saudáveis. Após 30 segundos, o pod ganha outra chance. Se falhar de novo, tempo de ejeção dobra. Isso é exponential backoff no nível de infraestrutura.
5. Fault Injection
Chaos engineering sem instalar nada.
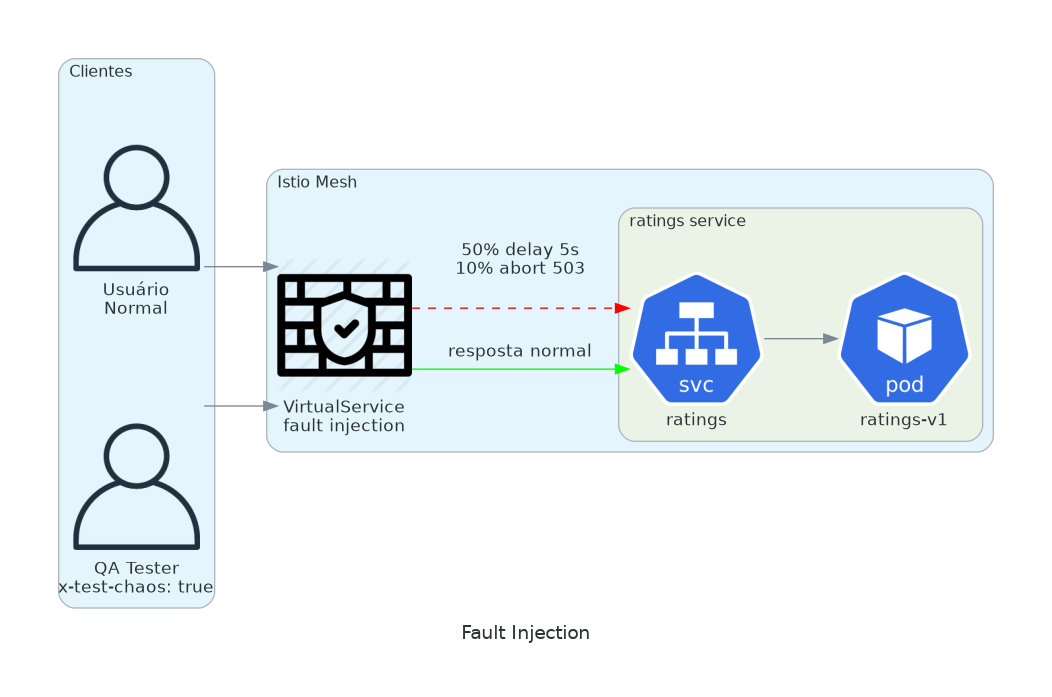 Injete latência. Injete erros. Veja o que quebra.
Injete latência. Injete erros. Veja o que quebra.
Seu sistema diz que lida com falhas graciosamente. Prove. Injete um delay de 5 segundos no seu serviço de pagamento. A página de checkout mostra um spinner, ou crasha?
O melhor momento pra descobrir é durante um teste planejado, não durante a Black Friday.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: ratings-fault
spec:
hosts:
- ratings
http:
- match:
- headers:
x-test-chaos:
exact: "true"
fault:
delay:
percentage:
value: 50
fixedDelay: 5s
abort:
percentage:
value: 10
httpStatus: 503
route:
- destination:
host: ratings
- route:
- destination:
host: ratingsHeader x-test-chaos: true ativa o chaos. 50% dos requests ganham 5s de delay. 10% retornam 503. Produção normal segue intacta. Rode sua suite de testes com o header. Veja o que acontece.
6. Locality Load Balancing
Pods em múltiplas regiões.
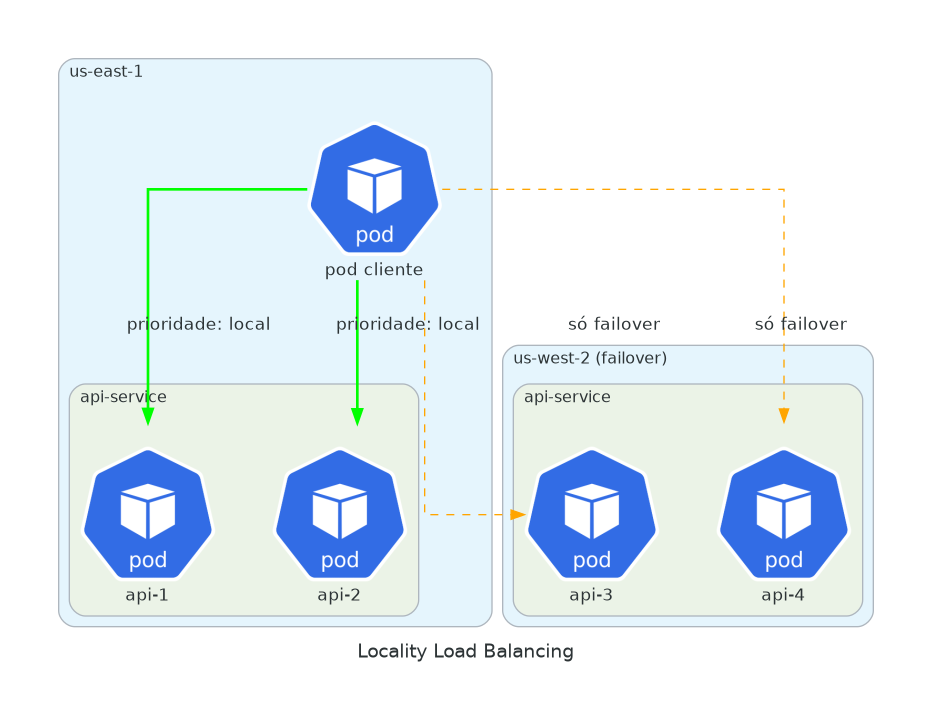 Você quer requests locais primeiro. Failover quando necessário.
Você quer requests locais primeiro. Failover quando necessário.
Latência cross-region acumula. Um request de São Paulo batendo em um pod na Virgínia adiciona 150ms de latência de rede. Multiplique por cada serviço na cadeia de chamadas.
Roteamento locality-aware mantém tráfego local quando possível. Mesma zona primeiro, depois mesma região, depois failover pra outras regiões.
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: geo-aware-lb
spec:
host: api-service
trafficPolicy:
loadBalancer:
localityLbSetting:
enabled: true
failover:
- from: us-east-1
to: us-west-2
- from: eu-west-1
to: eu-central-1
outlierDetection:
consecutive5xxErrors: 5
interval: 10s
baseEjectionTime: 30sRequest de us-east-1 vai pra pod em us-east-1. Se todos falharem, us-west-2 assume. Usuários ganham menor latência. Você paga menos por transferência de dados cross-region.
7. Egress Gateway
Compliance quer saber todo tráfego saindo do cluster.
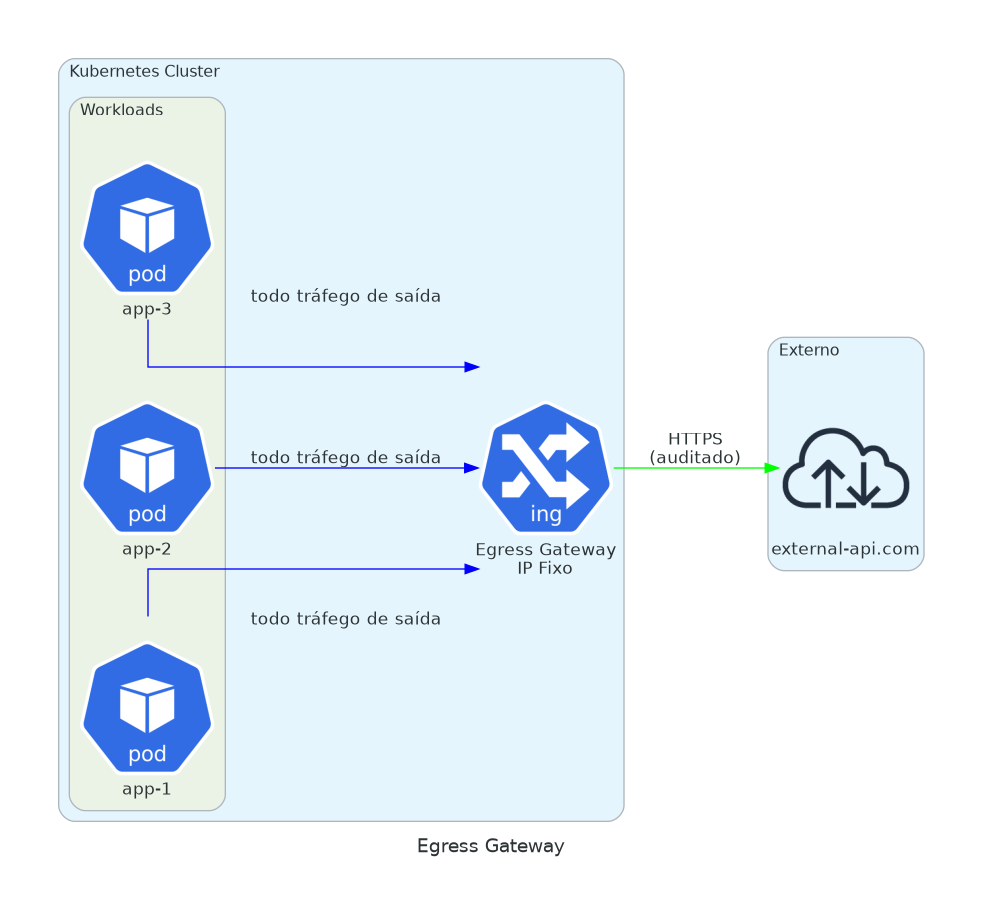 Você quer IPs de saída fixos.
Você quer IPs de saída fixos.
Algumas APIs externas exigem IP allowlisting. Seus pods têm IPs efêmeros. O egress gateway te dá um único ponto de saída com IP previsível.
Bônus: logging centralizado pra todo tráfego externo. Quando o time de segurança perguntar “quais serviços externos chamamos?”, você tem a resposta.
apiVersion: networking.istio.io/v1
kind: ServiceEntry
metadata:
name: external-api
spec:
hosts:
- external-api.com
location: MESH_EXTERNAL
ports:
- number: 443
name: https
protocol: TLS
resolution: DNS
---
apiVersion: networking.istio.io/v1
kind: Gateway
metadata:
name: istio-egressgateway
spec:
selector:
istio: egressgateway
servers:
- port:
number: 443
name: https
protocol: HTTPS
hosts:
- external-api.com
tls:
mode: PASSTHROUGHTodo tráfego externo passa por um ponto. Logs centralizados. IPs previsíveis pra allowlists. Trilha de auditoria pra compliance.
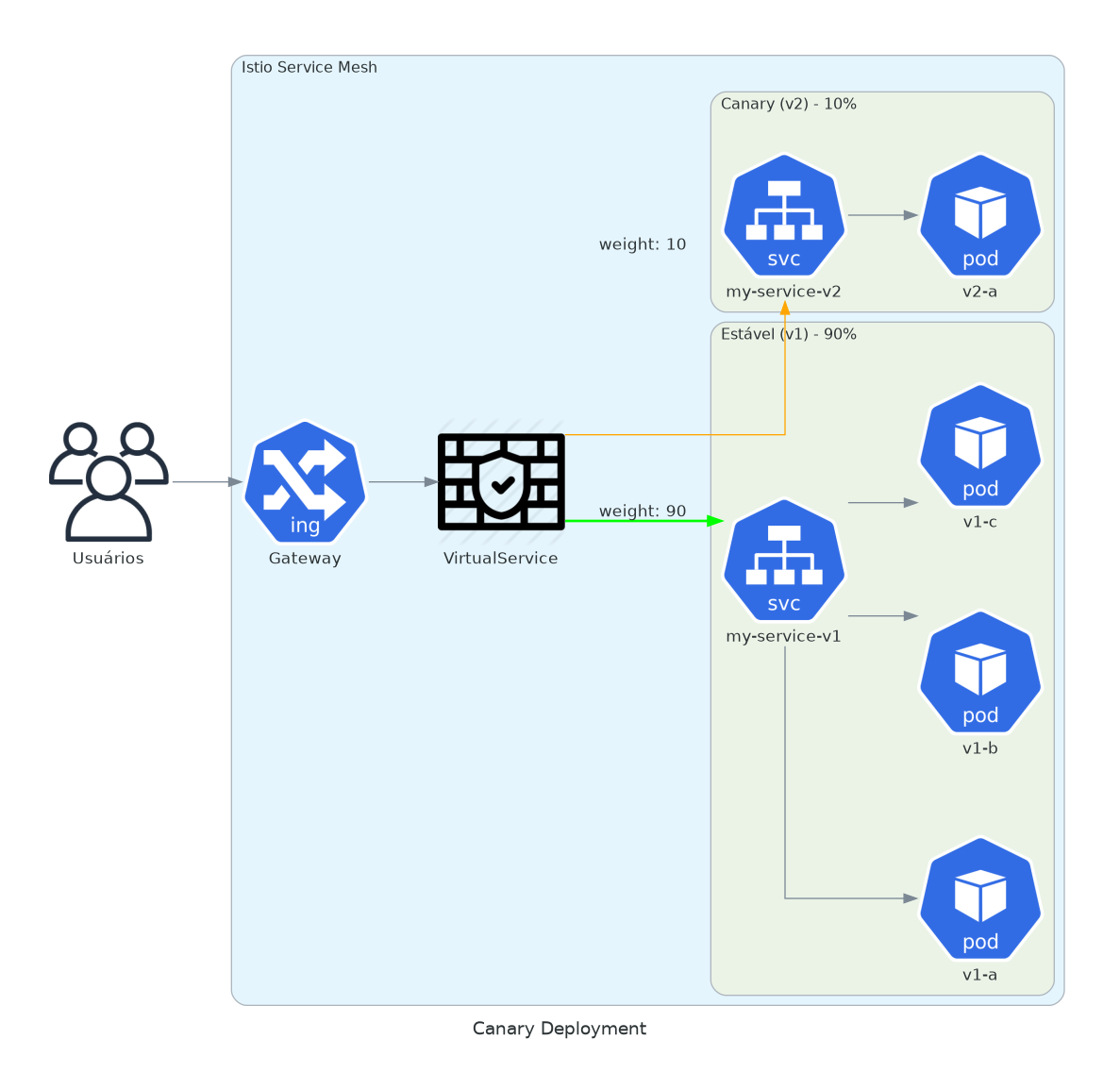
8. Canary com Weights
Deploy progressivo. 10% na nova versão. Monitore. Aumente.
Canary releases limitam o blast radius. Se v2 tem um bug, só 10% dos usuários veem. Você pega o problema nas métricas antes de virar um incidente.
Isso é diferente de rolling updates do Kubernetes. Com rolling updates, você substitui pods. Com weights do Istio, você controla distribuição de tráfego independente da quantidade de pods. Você pode ter 10 pods v2 recebendo 1% do tráfego.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: canary-deploy
spec:
hosts:
- my-service
http:
- route:
- destination:
host: my-service
subset: stable
weight: 90
- destination:
host: my-service
subset: canary
weight: 10
---
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: my-service-versions
spec:
host: my-service
subsets:
- name: stable
labels:
version: v1
- name: canary
labels:
version: v2Mude o weight. Aplique. Sem redeploy. Observe taxas de erro. Se v2 parecer bom, aumente pra 50%. Depois 100%. Se algo quebrar, defina canary pra 0%. Rollback instantâneo.
9. Teste A/B com Headers
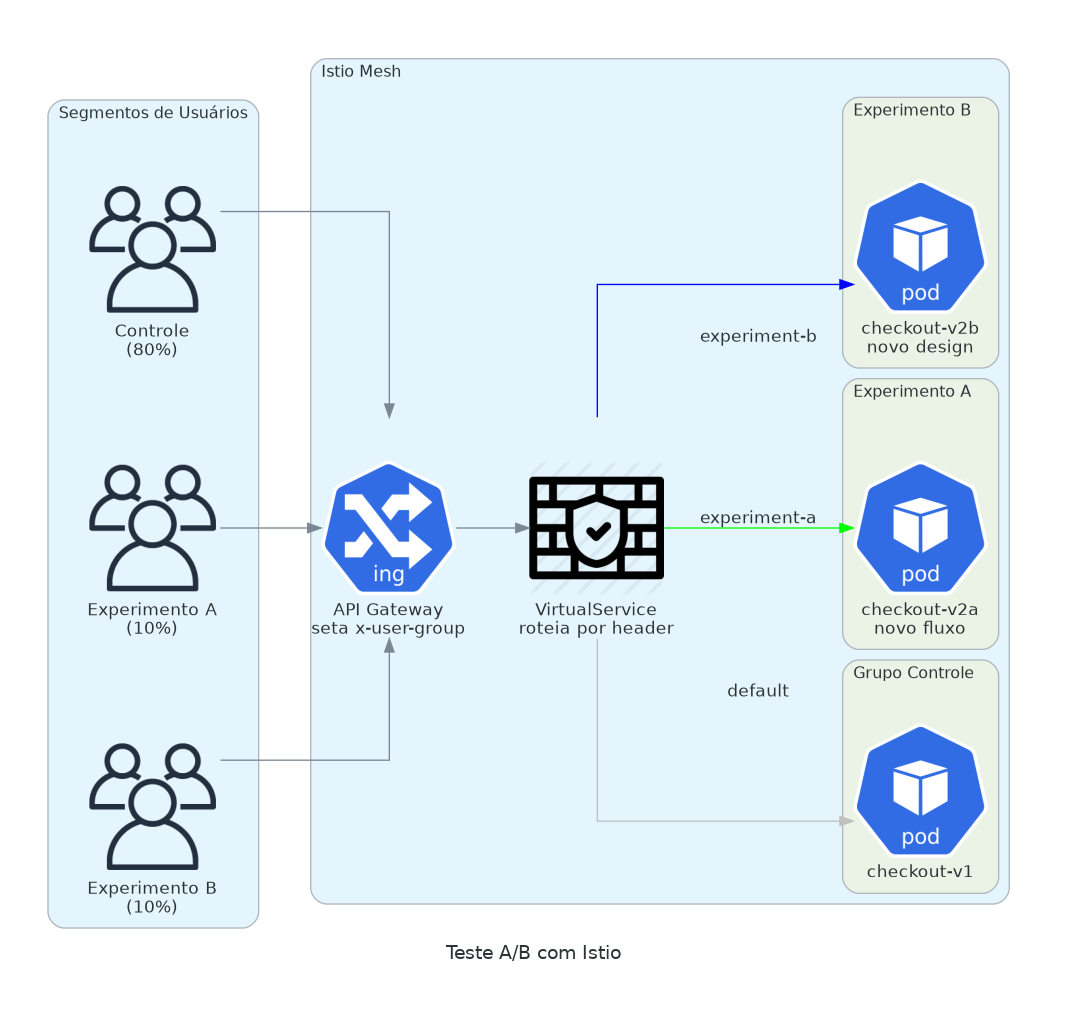
Teste diferentes experiências para diferentes segmentos de usuários. Sem deployar feature flags no seu código.
Marketing quer testar um novo fluxo de checkout. Data science quer comparar algoritmos de recomendação. Produto quer validar um redesign com usuários beta.
Todos esses são decisões de roteamento. Roteie por header, por cookie, por user agent. A aplicação não precisa saber.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: ab-testing
spec:
hosts:
- api-service
http:
- match:
- headers:
x-user-group:
exact: "experiment-a"
route:
- destination:
host: api-service
subset: experiment-a
- match:
- headers:
x-user-group:
exact: "experiment-b"
route:
- destination:
host: api-service
subset: experiment-b
- route:
- destination:
host: api-service
subset: controlSeu edge proxy ou API gateway seta o header baseado no segmento do usuário. Istio roteia pra versão certa. Você mede taxas de conversão pra cada variante. Quando o experimento termina, remova as regras do VirtualService.
10. Timeouts e Retries
Defaults sãos pra resiliência de rede.
 Sem mudar código da aplicação.
Sem mudar código da aplicação.
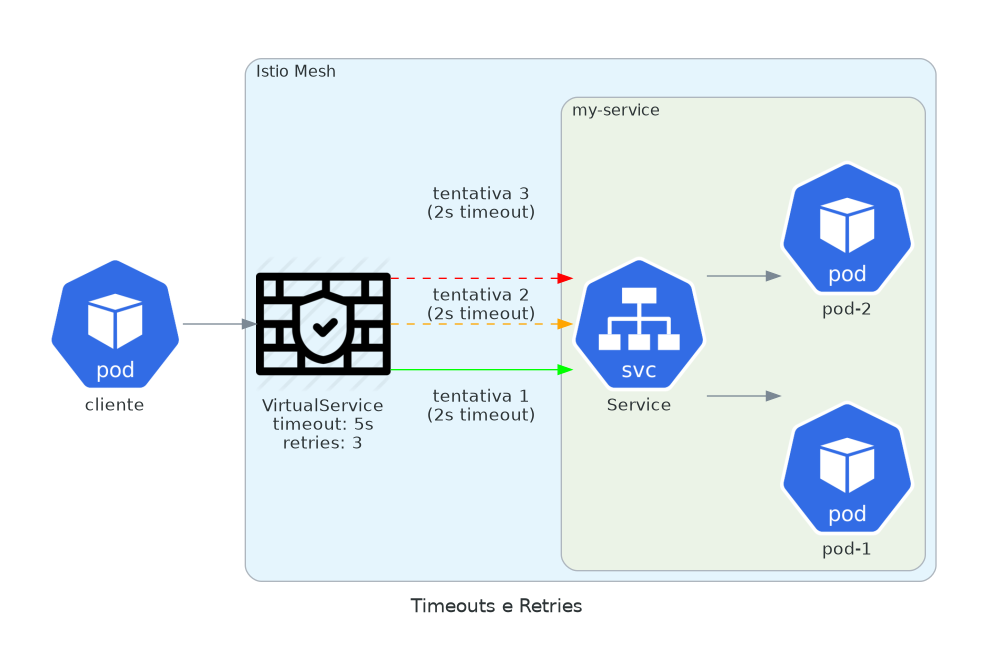
Sua aplicação provavelmente tem timeouts hardcoded. Alguns serviços têm timeout de 30 segundos. Outros não têm nenhum. Alguns fazem retry em qualquer erro. Outros não fazem retry.
Istio permite que você force políticas consistentes em todos os serviços. Timeout após 5 segundos. Retry 3 vezes em erros de conexão. Sem mudanças de código.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: resilient-service
spec:
hosts:
- my-service
http:
- route:
- destination:
host: my-service
timeout: 5s
retries:
attempts: 3
perTryTimeout: 2s
retryOn: gateway-error,connect-failure,refused-streamTimeout total de 5 segundos. Cada tentativa tem timeout de 2 segundos. Retries só em erros de rede, não em respostas 4xx. Esses são os defaults que previnem falhas em cascata.
Conclusão
A maioria dos times adota Istio por mTLS e métricas. Param aí.
As features deste artigo são onde está a alavancagem. Transformam infraestrutura em redução de risco. Releases mais rápidos. Menos incidentes. Problemas pegos antes dos usuários perceberem.
Comece com uma. Canary deployments ou circuit breakers. Depois adicione outra. Cada uma compõe.
A melhor infraestrutura é invisível até você precisar dela. Aí ela salva seu trimestre.