10 Istio Features You're Probably Not Using
What Is Istio
Istio is a service mesh for Kubernetes. It intercepts all traffic between your services and adds capabilities your application doesn’t need to implement: automatic mTLS, metrics, tracing, traffic control.
Here’s how it works. A sidecar proxy (Envoy) gets injected into each pod. This proxy captures all inbound and outbound traffic. The Istio control plane configures these proxies. (There’s also a newer “ambient mode” that removes the sidecar entirely. That’s a topic for another post.)
The result: observability, security, and traffic control without changing a single line of application code.
Three basic resources:
- Gateway: exposes services outside the cluster
- VirtualService: defines routing rules
- DestinationRule: configures traffic policies for a destination
If you only use these, you’re missing 80% of what Istio can do.
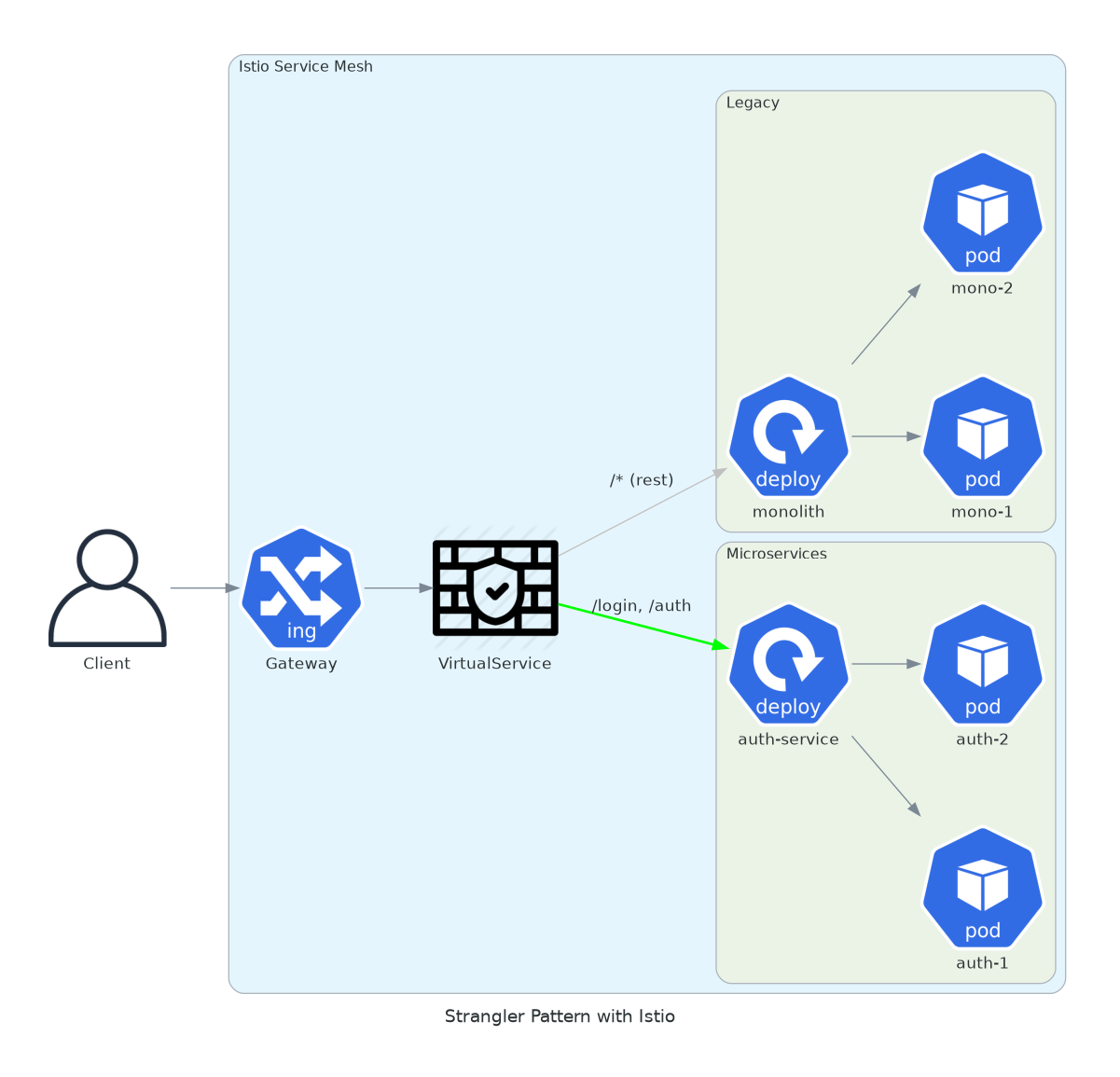
1. Strangler Pattern
You have a monolith at api.yourdomain.com. You want to extract /login to a microservice. No DNS changes. No downtime.
The strangler pattern lets you incrementally migrate functionality from a monolith to microservices. Instead of a risky big-bang rewrite, you route specific paths to new services while keeping everything else on the legacy system.
The VirtualService acts as a router. First match wins. Put your specific routes first, then a catch-all for the monolith.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: api-strangler
spec:
hosts:
- api.yourdomain.com
http:
- match:
- uri:
prefix: "/login"
- uri:
prefix: "/auth"
route:
- destination:
host: auth-service.auth.svc.cluster.local
port:
number: 8080
- route:
- destination:
host: monolith.legacy.svc.cluster.local
port:
number: 80Specific routes go to the microservice. Everything else stays on the monolith. Rollback means deleting the VirtualService. Zero coordination required with the legacy team.
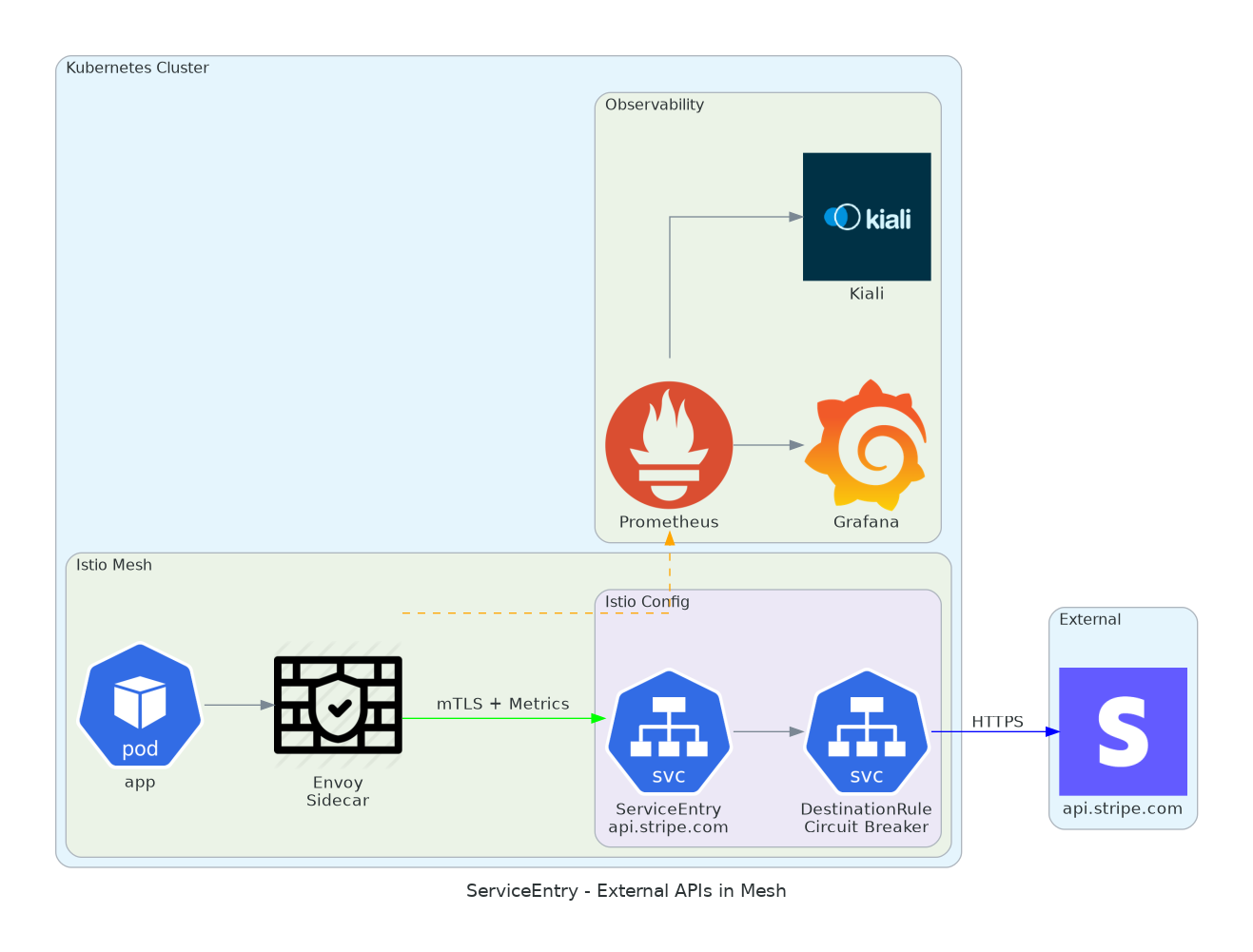
2. ServiceEntry for External APIs
Calls to Stripe, AWS, any external API. You want metrics. Circuit breaker. Observability in Kiali.
By default, Istio doesn’t know about external services. They don’t appear in your service graph. You can’t apply traffic policies to them. ServiceEntry changes that.
Once you declare an external service, Istio treats it like any other service in your mesh. You get latency histograms, error rates, connection pool limits. When Stripe has an outage, you’ll see it in Grafana before your users complain.
apiVersion: networking.istio.io/v1
kind: ServiceEntry
metadata:
name: stripe-api
spec:
hosts:
- api.stripe.com
location: MESH_EXTERNAL
ports:
- number: 443
name: https
protocol: TLS
resolution: DNS
---
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: stripe-api-dr
spec:
host: api.stripe.com
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
h2UpgradePolicy: UPGRADE
http1MaxPendingRequests: 50
outlierDetection:
consecutive5xxErrors: 5
interval: 30s
baseEjectionTime: 60sThe DestinationRule adds a circuit breaker. If Stripe returns 5 consecutive 5xx errors, Istio stops sending requests for 60 seconds. Your application gets fast failures instead of hanging connections.
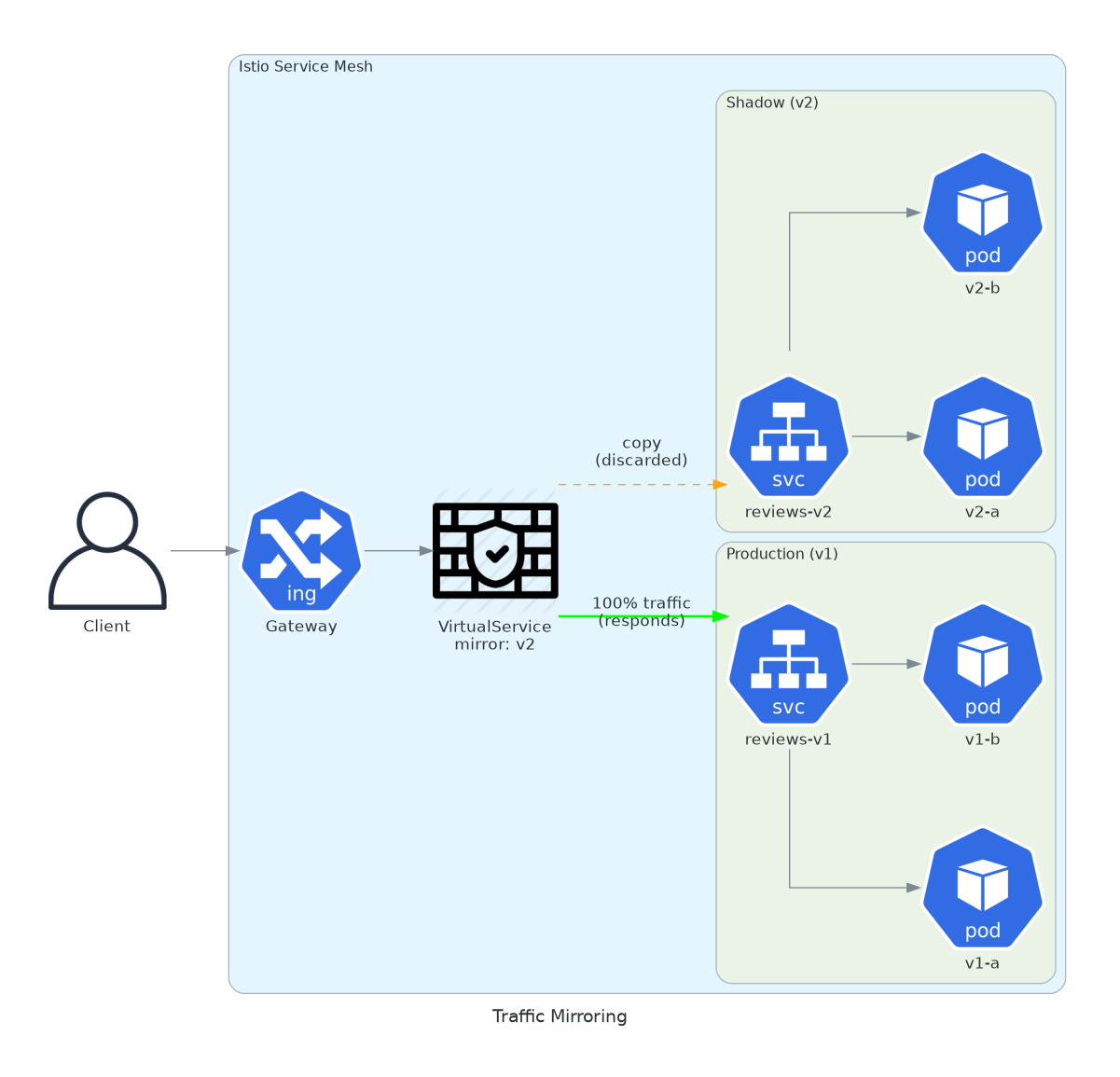
3. Traffic Mirroring
New version of your service. You want to test with real traffic. Without affecting users.
Shadow testing is underrated. You deploy v2 alongside v1. Real production traffic hits both. But only v1 responses go back to users. v2 responses are discarded.
What you get: real load testing, real data, real edge cases. Your staging environment lies to you. Production traffic doesn’t.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: reviews-mirror
spec:
hosts:
- reviews
http:
- route:
- destination:
host: reviews
subset: v1
weight: 100
mirror:
host: reviews
subset: v2
mirrorPercentage:
value: 100.0Watch v2 logs and metrics. If it handles traffic correctly, proceed to canary. If it crashes under load, you caught it before any user noticed. The mirrored requests are fire-and-forget. They add latency to v2, not to the client.
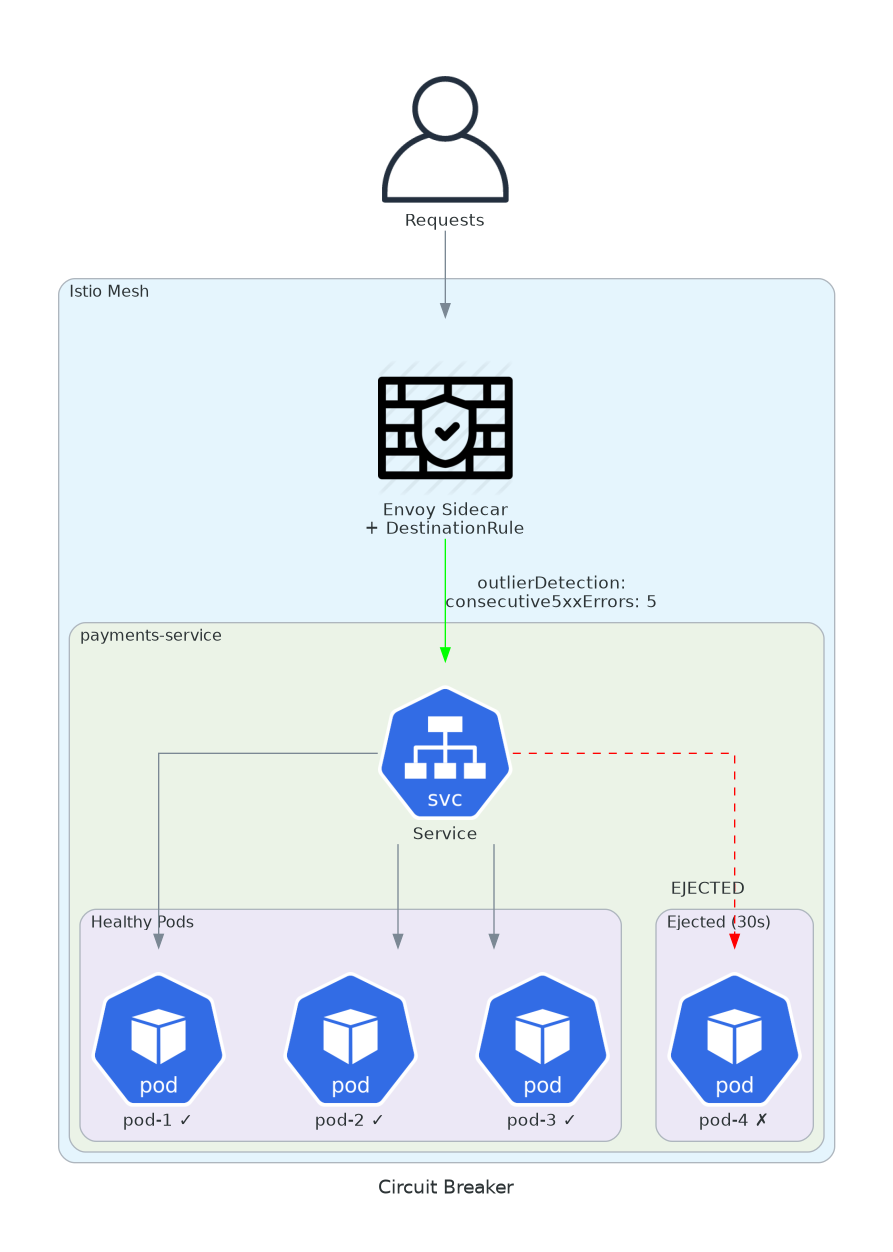
4. Circuit Breaker
A slow pod takes down the entire chain. Requests queue. Timeouts propagate. Cascade failure.
Distributed systems fail in distributed ways. One slow database query makes a pod slow. Callers wait. Their callers wait. Eventually your entire platform is waiting on one pod.
Circuit breakers stop the cascade. If a pod is unhealthy, remove it from the pool. Fast failure is better than slow failure.
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: payments-circuit-breaker
spec:
host: payments-service
trafficPolicy:
connectionPool:
tcp:
maxConnections: 100
http:
http1MaxPendingRequests: 50
http2MaxRequests: 100
maxRequestsPerConnection: 10
maxRetries: 3
outlierDetection:
consecutive5xxErrors: 5
interval: 10s
baseEjectionTime: 30s
maxEjectionPercent: 50
minHealthPercent: 30Five consecutive 5xx errors: pod ejected for 30 seconds. Traffic redirected to healthy pods. After 30 seconds, the pod gets a chance again. If it fails again, ejection time doubles. This is exponential backoff at the infrastructure level.
5. Fault Injection
Chaos engineering without installing anything.
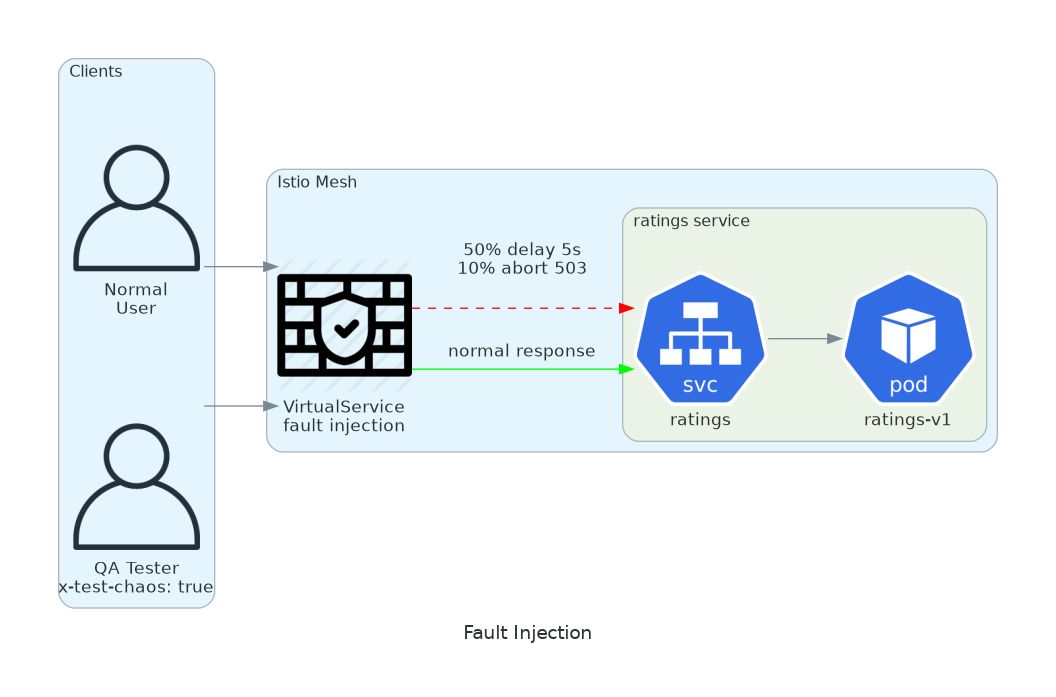 Inject latency. Inject errors. See what breaks.
Inject latency. Inject errors. See what breaks.
Your system claims to handle failures gracefully. Prove it. Inject a 5-second delay into your payment service. Does the checkout page show a spinner, or does it crash?
The best time to find out is during a planned test, not during Black Friday.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: ratings-fault
spec:
hosts:
- ratings
http:
- match:
- headers:
x-test-chaos:
exact: "true"
fault:
delay:
percentage:
value: 50
fixedDelay: 5s
abort:
percentage:
value: 10
httpStatus: 503
route:
- destination:
host: ratings
- route:
- destination:
host: ratingsHeader x-test-chaos: true activates chaos. 50% of requests get 5s delay. 10% return 503. Normal production stays untouched. Run your test suite with the header. Watch what happens.
6. Locality Load Balancing
Pods in multiple regions.
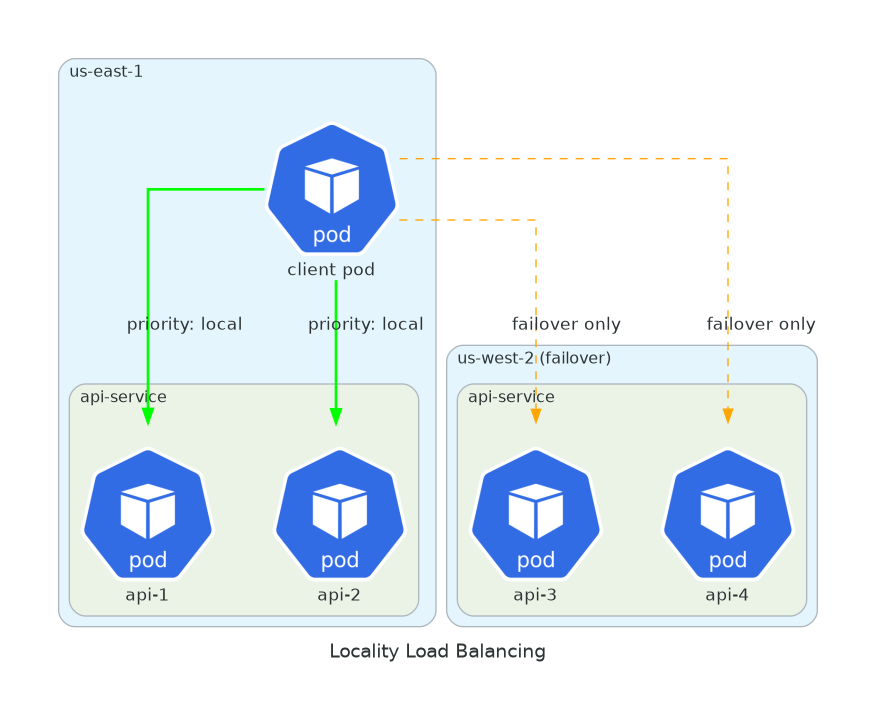 You want local requests first. Failover when needed.
You want local requests first. Failover when needed.
Cross-region latency adds up. A request from São Paulo hitting a pod in Virginia adds 150ms of network latency. Multiply by every service in the call chain.
Locality-aware routing keeps traffic local when possible. Same zone first, then same region, then failover to other regions.
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: geo-aware-lb
spec:
host: api-service
trafficPolicy:
loadBalancer:
localityLbSetting:
enabled: true
failover:
- from: us-east-1
to: us-west-2
- from: eu-west-1
to: eu-central-1
outlierDetection:
consecutive5xxErrors: 5
interval: 10s
baseEjectionTime: 30sRequests from us-east-1 go to pods in us-east-1. If all fail, us-west-2 takes over. Users get lower latency. You pay less for cross-region data transfer.
7. Egress Gateway
Compliance wants to know all traffic leaving the cluster.
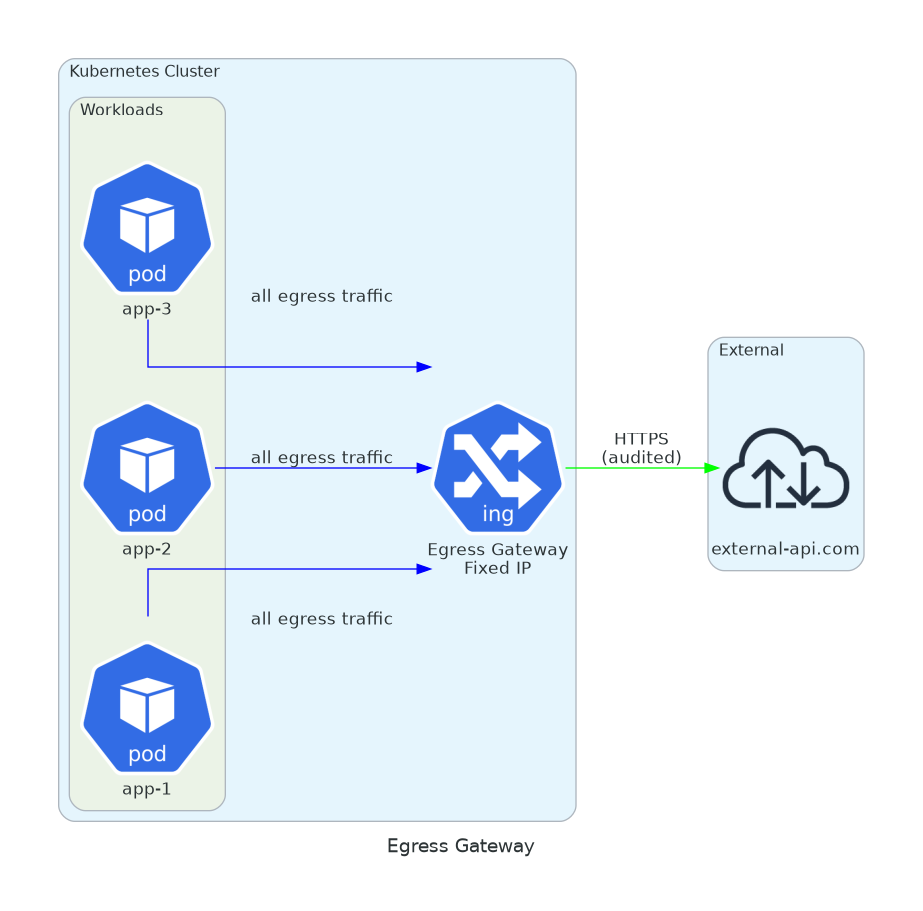 You want fixed egress IPs.
You want fixed egress IPs.
Some external APIs require IP allowlisting. Your pods have ephemeral IPs. The egress gateway gives you a single exit point with a predictable IP.
Bonus: centralized logging for all external traffic. When the security team asks “what external services do we call?”, you have the answer.
apiVersion: networking.istio.io/v1
kind: ServiceEntry
metadata:
name: external-api
spec:
hosts:
- external-api.com
location: MESH_EXTERNAL
ports:
- number: 443
name: https
protocol: TLS
resolution: DNS
---
apiVersion: networking.istio.io/v1
kind: Gateway
metadata:
name: istio-egressgateway
spec:
selector:
istio: egressgateway
servers:
- port:
number: 443
name: https
protocol: HTTPS
hosts:
- external-api.com
tls:
mode: PASSTHROUGHAll external traffic through a single point. Centralized logs. Predictable IPs for allowlists. Audit trail for compliance.
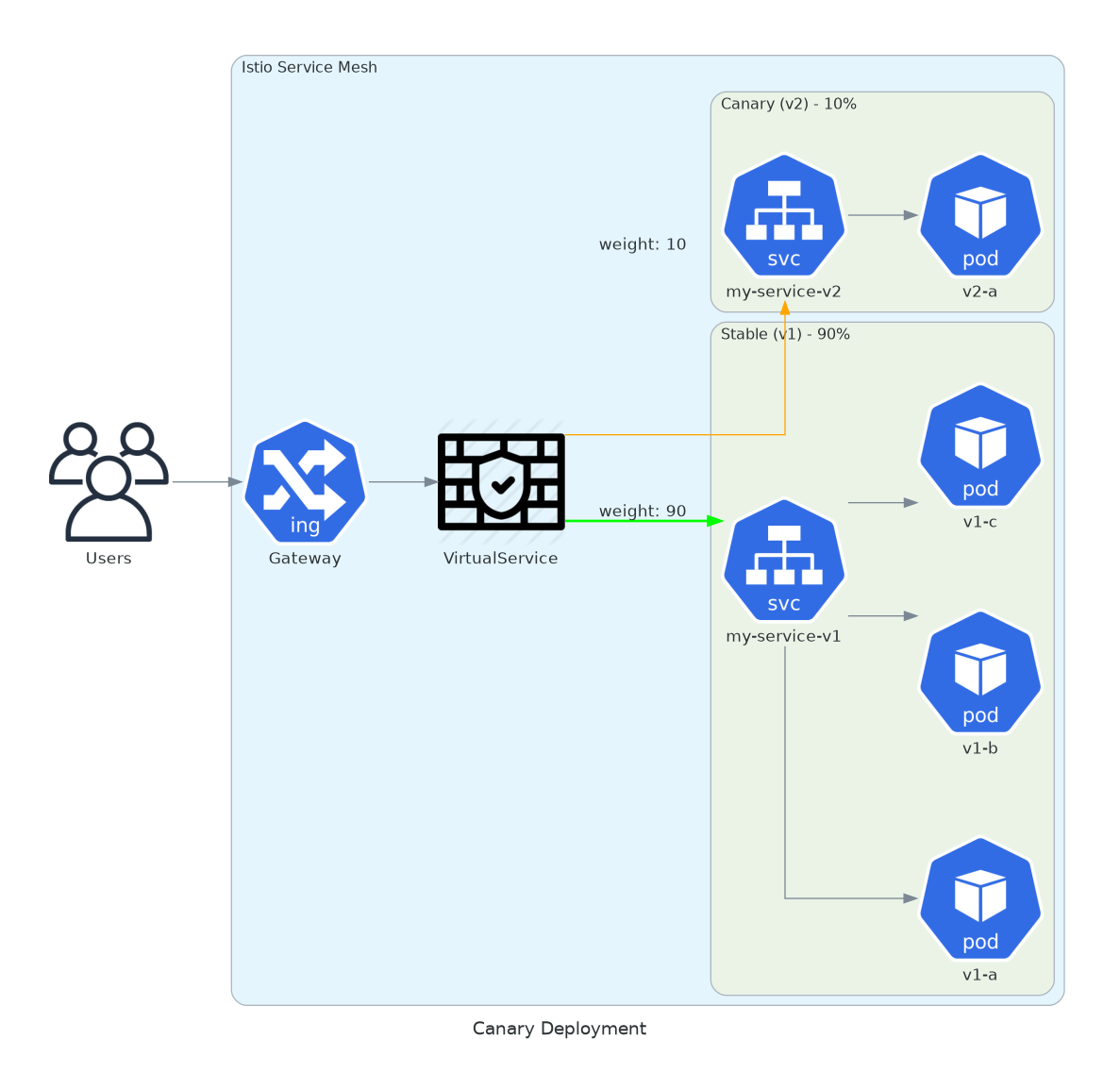
8. Canary with Weights
Progressive deployment. 10% on the new version. Monitor. Increase.
Canary releases limit blast radius. If v2 has a bug, only 10% of users see it. You catch the problem in metrics before it becomes an incident.
This is different from Kubernetes rolling updates. With rolling updates, you replace pods. With Istio weights, you control traffic distribution independently of pod count. You can have 10 v2 pods receiving 1% of traffic.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: canary-deploy
spec:
hosts:
- my-service
http:
- route:
- destination:
host: my-service
subset: stable
weight: 90
- destination:
host: my-service
subset: canary
weight: 10
---
apiVersion: networking.istio.io/v1
kind: DestinationRule
metadata:
name: my-service-versions
spec:
host: my-service
subsets:
- name: stable
labels:
version: v1
- name: canary
labels:
version: v2Change the weight. Apply. No redeploy. Watch error rates. If v2 looks good, bump to 50%. Then 100%. If something breaks, set canary to 0%. Instant rollback.
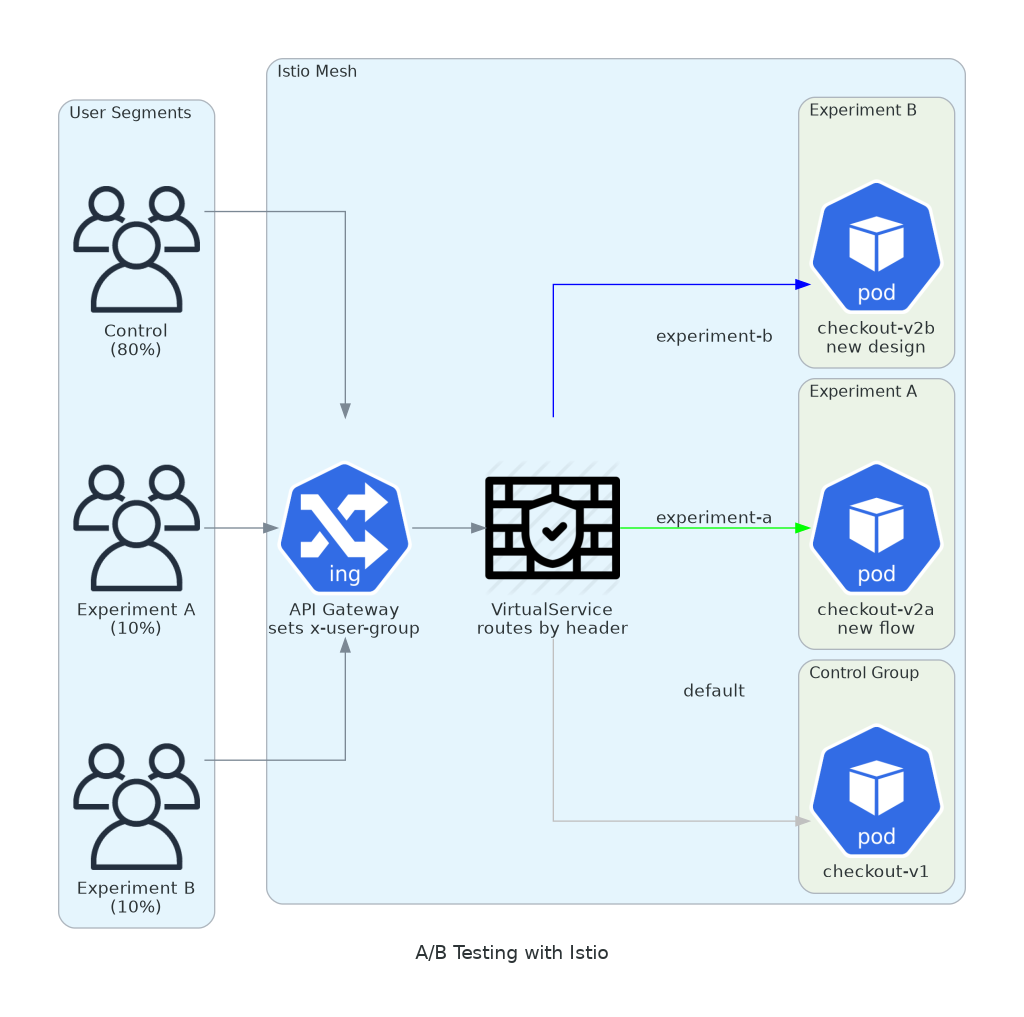
9. A/B Testing with Headers
Test different experiences for different user segments. Without deploying feature flags in your code.
Marketing wants to test a new checkout flow. Data science wants to compare recommendation algorithms. Product wants to validate a redesign with beta users.
All of these are routing decisions. Route by header, by cookie, by user agent. The application doesn’t need to know.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: ab-testing
spec:
hosts:
- api-service
http:
- match:
- headers:
x-user-group:
exact: "experiment-a"
route:
- destination:
host: api-service
subset: experiment-a
- match:
- headers:
x-user-group:
exact: "experiment-b"
route:
- destination:
host: api-service
subset: experiment-b
- route:
- destination:
host: api-service
subset: controlYour edge proxy or API gateway sets the header based on user segment. Istio routes to the right version. You measure conversion rates for each variant. When the experiment ends, remove the VirtualService rules.
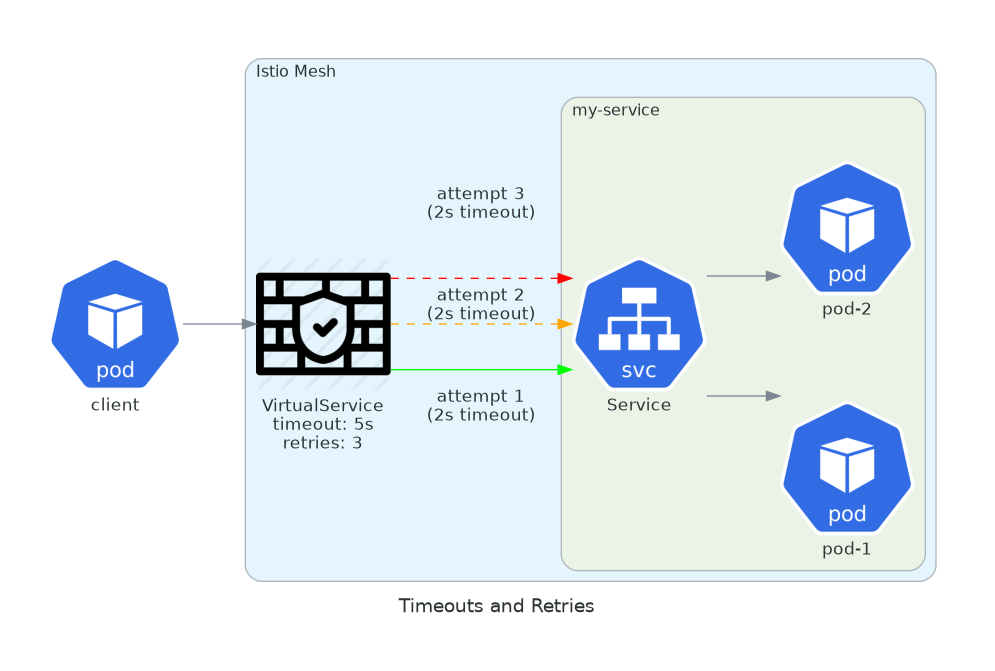
10. Request Timeouts and Retries
Sane defaults for network resilience.
 Without changing application code.
Without changing application code.
Your application probably has hardcoded timeouts. Some services have 30-second timeouts. Others have none. Some retry on any error. Others don’t retry at all.
Istio lets you enforce consistent policies across all services. Timeout after 5 seconds. Retry 3 times on connection errors. No code changes required.
apiVersion: networking.istio.io/v1
kind: VirtualService
metadata:
name: resilient-service
spec:
hosts:
- my-service
http:
- route:
- destination:
host: my-service
timeout: 5s
retries:
attempts: 3
perTryTimeout: 2s
retryOn: gateway-error,connect-failure,refused-streamTotal timeout of 5 seconds. Each attempt times out at 2 seconds. Retries only on network errors, not on 4xx responses. These are the kind of defaults that prevent cascading failures.
Conclusion
Most teams adopt Istio for mTLS and metrics. They stop there.
The features in this article are where the leverage is. They turn infrastructure into risk reduction. Faster releases. Fewer incidents. Problems caught before users notice.
Start with one. Canary deployments or circuit breakers. Then add another. Each one compounds.
The best infrastructure is invisible until you need it. Then it saves your quarter.